
A few weeks ago we wrote about how Open Source is coming for AI. At that time we didn't realize how quickly our predictions would start to be realized. In a new leaked document from inside Google, one of their AI team highlighted open source innovation as the primary competition for Google, OpenAI, and other large incumbent firms.
"We Have No Moat, and Neither Does OpenAI"
The memo, first shared on SemiAnalysis, is reported to be from "a researcher inside Google." Even if that is not true, the article itself comes from someone well-acquainted with the industry and how the competive field is changing.
The thesis of the memo is that Google and OpenAI do not have a sustainable competitive advantage in the field of large language models (and AI generally). For a long time, the creation of large AI models was considered too resource-intensive for anyone but very large companies to compete. But as soon as some reasonably open models were made available, the distributed, democratized open source community started making faster progress with fewer resources than had been considered possible:
While our models still hold a slight edge in terms of quality, the gap is closing astonishingly quickly. Open-source models are faster, more customizable, more private, and pound-for-pound more capable. They are doing things with $100 and 13B params that we struggle with at $10M and 540B. And they are doing so in weeks, not months.
The authors then show an annotated chart from the Vicuna 13-B announcement, adding "2 weeks apart" and "1 week apart" to show how quickly open source models evolved:
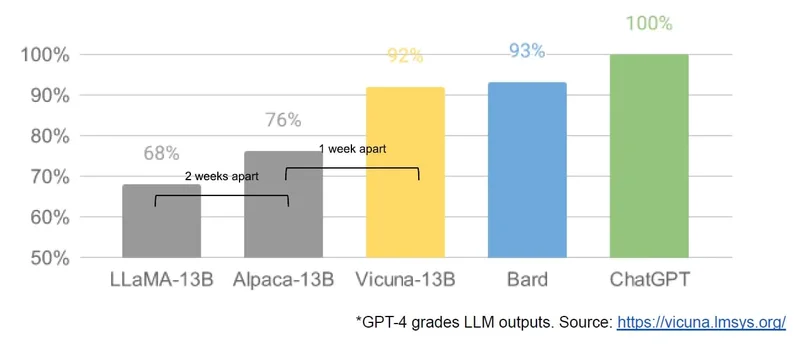
The authors continue:
A tremendous outpouring of innovation followed, with just days between major developments (see The Timeline for the full breakdown). Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc. etc. many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening, and a beefy laptop.
Getting Your OSPO Ready for AI
Every OSPO that we work with has been asked to start working on policies for AI, including how to integrate it, necessary controls, and data and model licensing. There is a lot of overlap between the work that OSPOs are already doing and the skills that are required to help manage AI in a corporate context.
What people may not realize is that right now people are considering "AI" and "Open Source" to be generally distinct policy areas. But the trend in the industry, and what the Google memo highlights, is that open source will be - and perhaps already is - the primary playing field for developing and working with AI technologies.
That means that you should start thinking about the classic open source issues now with an AI lens. From a compliance and security standpoint, what is your AI supply chain? How do you manage provenance? How do you manage licenses (and license incompatibilities)?
From a community standpoint, how can you align and cooperate with others? Can you create or participate in larger communities that are more powerful than your own organization?
And most importantly, how can you structure your AI policies and tools to encourage compliance and good habits without slowing down the business?
The next evolution of your OSPO might just depend on the answers.
