
It was a big week for Github CoPilot last week. There were new allegations of copyright infringement of open sourced code and an announced lawsuit. So how should you think about CoPilot and other machine learning tools trained on open source code?
The coming wave of machine learning (ML) tools
CoPilot is one of a number of recently-released machine-learning-based tools for creating art, writing, and code. To understand how they work and how they apply to open source, we need to take a minute to explain how they work. It doesn't require a lot of technical depth to get to the core issues.
Building and using an ML "model"
The first thing to understand about these ML tools is that they have two distinct parts. The first part is the creation of a "model" (we'll define that in a minute) and the second part uses the model to make new outputs - new sentences, new pictures, or new code.
The first thing to do when creating a new ML tool is to show it example inputs and have it take a bunch of measurements about the statistical probabilities of each input. This process is called "training." For example, some models that encode English text are created by trying to guess the next word in a sentence. If you process and record the "next word" probabilities over several billion sentences, then you have a pretty comprehensive idea of the range of possible "next words" in any sentence. Machine learning trained on pictures use similar tricks. For example, they may try to guess what color a particular pixel is given all its neighbors.
So what is a model? It is a a set of numbers that encode statistics about the inputs that have been processed during training. It doesn't include any of the materials that were used during training - at least, not in the usual sense. Even data scientists don't really understand all the ways in which the model has "learned" from the examples it was shown. What we do know is as more examples are used in the training process, the resulting model has a better, more coherent picture of the probabilities inherent in creative works.
Once the model has been trained, you can use the model to create new outputs. This process is called "inference." You do this by providing a prompt that is used to identify one of the trillions of possible probabilities. These probabilities are then processed in reverse order to create a new sentence, or artwork, or code function.
For example, fill in the blank in the phrase, "It was a dark and stormy ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲ ̲. If your mind naturally filled in the word "night," then congratulations - you just performed inference in way similar to how machine learning tools do it. Someone else might fill in the sentence with the word "sea" ("It was a dark and stormy sea"). While ending the sentence with the word "sea" might be lower probability than ending it with the word "night," it still makes sense, and so there is a certain probability that "sea" might be the next word. But you probably didn't fill in the word "elephant," because "It was a dark and stormy elephant" is an unlikely (low probability) conclusion to that sentence.
Models and copyright
Better models mean better outputs - and better models require more training material. The leading ML models available today leverage billions of individual training examples, almost all of which are copyrighted. The usual arguments for the legality of building a model are that 1) reading and calculating the mathematical relationships between parts of a work doesn't copy any expression, and 2) if it does, it is fair use.
The logic of this argument is straightforward: The creation of a model doesn't record anything except the statistical properties of the source works. For example, it isn't infringing anyone's copyright to count how often the word "the" appears in a story. Nothing that makes the story unique - none of the expression - has been copied in the process of building a statistical picture of the story. However, counting words and how often they show up is not too far from what machine learning processes do to process an input. Further, there is no clear way to separate out the probabilities associated with any one input in the training.
But there is a specific danger associated with creating models, and that is known as "overtraining." This is what happens when the model records the properties of a source work with such high fidelity that the source work can be exactly or mostly reproduced through inference, as long as the correct prompt is used.
Being able to regenerate one of the inputs changes the way we think about the model. Instead of the model being simply a record of non-specific statistics, it becomes a way to compress and package specific inputs and let them be re-generated on command. This shift from measurement to compression changes the copyright analysis, making it easier to claim that the entire process (training and inference) infringes the copyright of the source works.
And that brings us to this week's news.
CoPilot and code generation
CoPilot is a code generation tool that was trained on source code, and is used to automatically create functions under the direction of a software developer. When CoPilot was first demonstrated, it seemed to be nearly magic, promising a huge gain in programmer productivity. A follow-up study (also by Github) found that developer productivity and happiness increased when using CoPilot.
CoPilot, like other ML tools, was trained on billions of lines of source code in order to create its model - specifically, the open source code housed at Github. So it wasn't surprising when someone found out that they could recreate their source code using CoPilot.
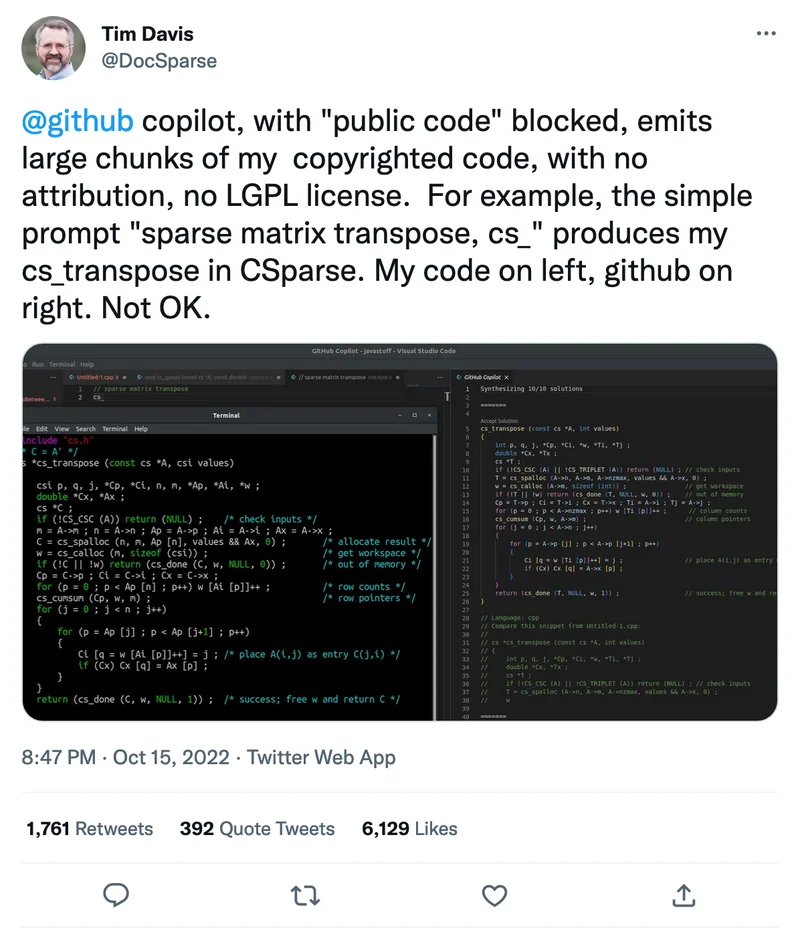
If you can't read the tiny text, what it shows is that CoPilot successfully re-created functions and comments that were originally written by this professor, Tim Davis. ( Original Tweet ) While there are some trivial differences, the similarity is clear. Further, this is not the first time that people have been able to prompt CoPilot to create specific known code. Github has a procedure for detecting and preventing the direct reproduction of existing code, but it apparently fails in at least some cases.
For source code hosted on Github, Github appears to have sufficient rights to create the model. Github's terms of service grant Github a broad license "to do things like copy [your uploaded source code] to our database and make backups; show it to you and other users; parse it into a search index or otherwise analyze it on our servers; [and] share it with other users."
For anyone using CoPilot, however, the big question is whether using CoPilot may inadvertently lead to copyright infringement. Even code provided under the most permissive licenses still requires attribution and the maintenance of copyright notices. A CoPilot-created snippet will likely not include those parts. And for code licensed under reciprocal licenses like the GPL, incorporating the code into your product may result in the inadvertent creation of a derivative work covered under the GPL. A number of prominent open source developers have expressed the opinion that one use of CoPilot would be the "laundering" of source code through the process to remove unwelcome license constraints.
Lawyers engaged
These concerns may have previously been just hypothetical, but last week a number of lawyers in California announced an investigation into whether the use of CoPilot was leading to the infringement of various open source licenses. Quoting from the announcement of the investigation:
Copilot users—here’s one example, and another—have shown that Copilot can be induced to emit verbatim code from identifiable repositories.... Use of this code plainly creates an obligation to comply with its license. But as a side effect of Copilot’s design, information about the code’s origin—author, license, etc.—is stripped away. How can Copilot users comply with the license if they don’t even know it exists?
Copilot’s whizzy code-retrieval methods are a smokescreen intended to conceal a grubby truth: Copilot is merely a convenient alternative interface to a large corpus of open-source code. Therefore, Copilot users may incur licensing obligations to the authors of the underlying code.
So what now?
AI models are a very poor fit for any branch of IP law other than trade secrets (and not great there either, for many desired uses). Right now, the technology is far ahead of the law in terms of identifying what rights, if any, are in an ML model and how the different aspects of model usage (training, distribution, and inference) may or may not implicate copyright. We will definitely be discussing this much more as time goes on.
But for now, it might be worth having some caution associated with the use of CoPilot in your organization. That doesn't mean to not use it, but instead think about it in terms of risk. There may be some code in your organization that can easily be licensed as open source. There may be other code for which an open source license would be a significant problem. It may be worth restricting your use of CoPilot on the most sensitive code if you are an IP-centric organization.
When you do use CoPilot, make clear to your developers that its output should not be copied verbatim, but instead should be treated as a suggestion or starting point, and that the code should be adapted to fit your specific situation.
Finally, the use of CoPilot reinforces the importance of code scanning as a regular and ongoing part of code hygiene. In the end, the use of CoPilot is essentially the same as many other situations: an inexperienced or unthinking (or pressured) developer copies source code into your application in order to fix a bug, enhance a feature, or just make a deadline. Whether that code copying happens "by hand" or "by CoPilot" doesn't really matter - your processes should be set up to recognize and mitigate copying that might occur.
Update: More commentary on Github CoPilot
Michael Weinberg, Executive Director of NYU's Engelberg Center for Innovation Law and Policy, has an interesting blog post discussing the CoPilot litigation that we discussed last week. Weinberg highlights that many of the people concerned about CoPilot seem to be primarily concerned about the social effects of CoPilot on open source development, and less so on the legal analysis.
The CoPilot litigation investigation page argues:
By offering Copilot as an alternative interface to a large body of open-source code, Microsoft is doing more than severing the legal relationship between open-source authors and users. Arguably, Microsoft is creating a new walled garden that will inhibit programmers from discovering traditional open-source communities. Or at the very least, remove any incentive to do so. Over time, this process will starve these communities.
Weinberg disagrees, pointing out that there is already a convenient interface to a lot of open source code, called "Google." He doesn't see much difference between searching for source code on Google and receiving it from CoPilot. In both cases, Weinberg argues, most people are users of open source code, and very few are contributors.
I disagree with both of these points of view. As long as the legal questions around Github CoPilot can be worked out - and there are many potential issues - then CoPilot might actually lead to a new abundance of open source code. Why? Because CoPilot (and services like it) make creating code much cheaper and easier. And when it is cheaper and easier to create code, the natural result is that you will get more code created, by more people. This is true even if every line of code created by CoPilot will need to be reviewed, edited, and tweaked by a human. After all, re-writing is almost always easier than writing.
(H/T: Luis Villa )
Note: The image at the top of this article is generated by a machine learning tool called Stable Diffusion using the prompt "A robot typing on a keyboard at a computer, digital art"
